










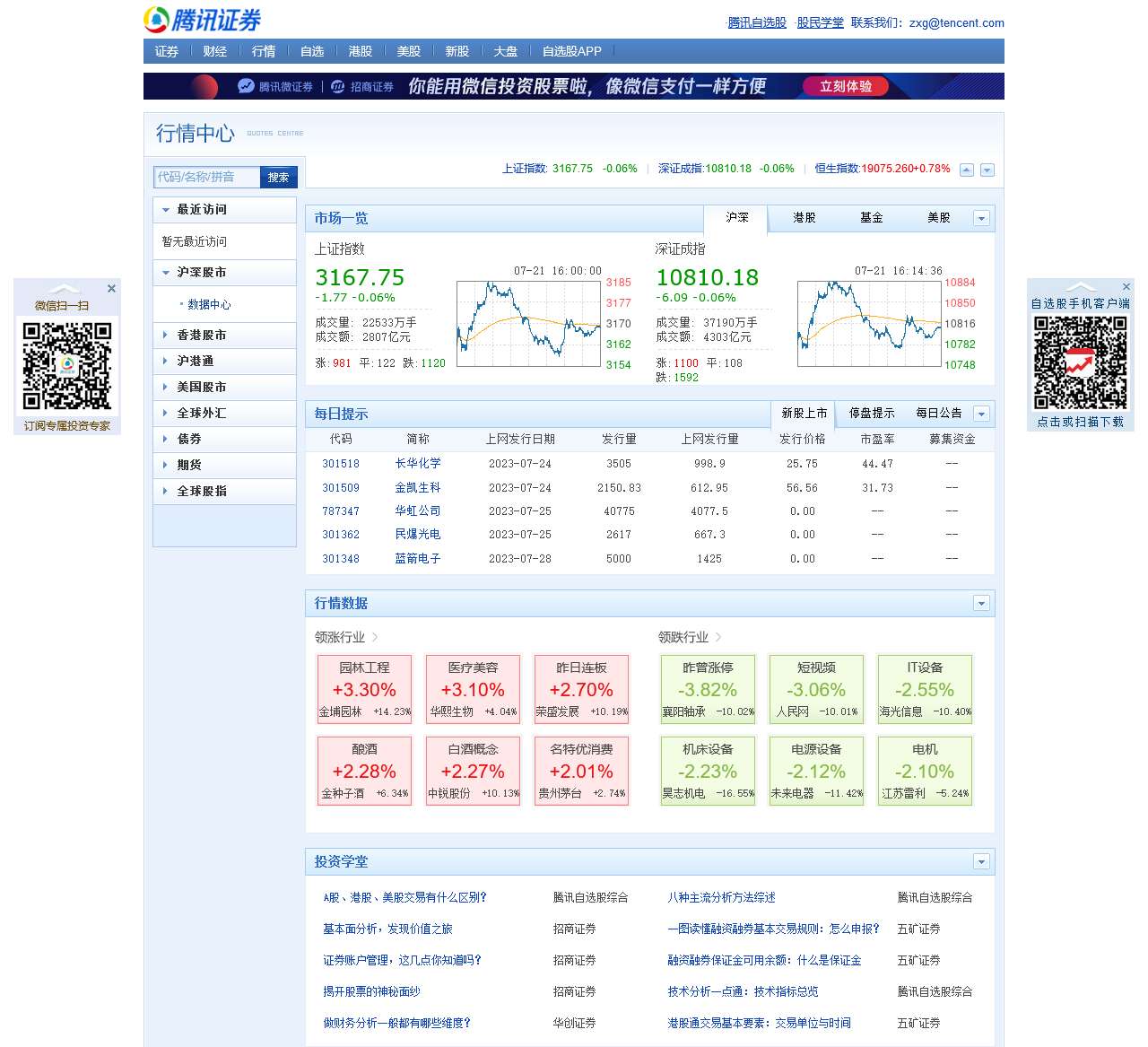
<table>
<tr>
<th>指数</th>
<th>当前点位</th>
</tr>
<tr>
<td>上证指数</td>
<td>301518</td>
</tr>
<tr>
<td>深证成指</td>
<td>301509</td>
</tr>
<tr>
<td>恒生指数</td>
<td>787347</td>
</tr>
<tr>
<td>道琼斯</td>
<td>301362</td>
</tr>
<tr>
<td>纳斯达克</td>
<td>301348</td>
</tr>
</table>
<table>
<tr>
<th>板块</th>
<th>个股名称</th>
</tr>
<tr>
<td>主板</td>
<td>长华化学, 金凯生科, 华虹公司, 民爆光电, 蓝箭电子</td>
</tr>
<tr>
<td>创业板</td>
<td>金埔园林, 华熙生物, 荣盛发展, 金种子酒, 中锐股份, 贵州茅台</td>
</tr>
<tr>
<td>A+H股</td>
<td>襄阳轴承, 人民网, 海光信息, 昊志机电, 未来电器, 江苏雷利</td>
</tr>
</table>
<table>
<tr>
<th>板块</th>
<th>个股名称</th>
</tr>
<tr>
<td>N三力</td>
<td>宁波联合, 白云机场, 博威合金, 神驰机电, 天安新材, 日辰股份, 晶方科技, 中航高科, 山西汾酒</td>
</tr>
<tr>
<td>江南高纤</td>
<td>商赢环球, 天龙股份, 美尔雅, 金发科技, 退市保千, 苏州龙杰, 国联股份, 金牛化工, 四方股份</td>
</tr>
</table>
<table>
<tr>
<th>重大股票</th>
<th>名称</th>
</tr>
<tr>
<td>贵州茅台</td>
<td>中国平安, 中信证券, 兆易创新, 通威股份, 闻泰科技, 恒生电子, 中信建投, 恒瑞医药, 金健米业</td>
</tr>
<tr>
<td>大陆在美上市公司</td>
<td>神驰机电, 神马电力, 金健米业, 良品铺子, 惠发食品, 恒银金融, 锦和商业, 中源家居, 建研院, 和顺石油</td>
</tr>
</table>
<table>
<tr>
<th colspan=”2″>热门问答</th>
</tr>
<tr>
<td>A股、港股、美股交易有什么区别?</td>
<td>基本面分析,发现价值之旅</td>
</tr>
<tr>
<td>证券账户管理,这几点你知道吗?</td>
<td>揭开股票的神秘面纱</td>
</tr>
<tr>
<td>做财务分析一般都有哪些维度?</td>
<td>八种主流分析方法综述</td>
</tr>
<tr>
<td>融资融券保证金可用余额:什么是保证金</td>
<td>技术分析一点通:技术指标总览</td>
</tr>
</table>
<table>
<tr>
<th>排行</th>
<th>股票</th>
</tr>
<tr>
<td>港股通涨幅排行</td>
<td>金斯瑞生物科, 叮当健康, 瑞尔集团, 东方甄选, 云顶新耀-B</td>
</tr>
<tr>
<td>沪港通溢价排行</td>
<td>华能国际, 皖通高速, 民生银行, 中远海能, 华电国际</td>
</tr>
<tr>
<td>沪股通涨幅排行</td>
<td>南方传媒, 广西广电, 飞科电器, 嘉必优, 永和股份</td>
</tr>
</table>
<span>行情红</span>, <span>行情绿</span>, <span>行情平</span>,及其他<span>#333</span>的字体和链接
<span>浅灰提示色</span>
<span>股票名称</span>超链
数字字体,Tahoma
<span>0123456789</span>
<span>使用class设置字体大小10(自动调整line-height)</span>
<span>使用class设置字体大小11(自动调整line-height)</span>
<span>使用class设置字体大小12(自动调整line-height)</span>
<span>使用class设置字体大小14(自动调整line-height)</span>
<span>使用class设置字体大小15(自动调整line-height)</span>
<span>使用class设置字体大小16(自动调整line-height)</span>
<span>使用class设置字体大小17(自动调整line-height)</span>
<span>使用class设置字体大小18(自动调整line-height)</span>
<span>使用class设置字体大小19(自动调整line-height)</span>
<span>使用class设置字体大小20(自动调整line-height)</span>
-
域名信息
注册人/机构:MarkMonitor Information Technology (Shanghai) Co.,Ltd.
注册人邮箱:-
域名年龄:28年2个月17天(过期时间为2031年07月27日)
-
备案信息
备案号:粤B2-20090059
名称:深圳市腾讯计算机系统有限公司
性质:企业
审核时间:2023-07-18
-
网站信息
IP:183.47.103.103[中国广东惠州 电信]
数据统计
数据评估
本站血鸟导航提供的行情中心_财经频道_腾讯网相关数据内容都来源于网络或站长收集,不保证外部链接和内容的准确性和完整性,同时,对于该外部链接的指向,不由血鸟导航实际控制,在2023年7月29日 上午10:01收录时,该网页上的内容,都属于合规合法,后期网页的内容如出现违规或不对称,欢迎联系我们邮箱进行删除或更改,血鸟导航不承担任何责任。
相关导航







 赣公网安备36020002000448号
赣公网安备36020002000448号