










Claude是一款基于大规模语言模型的智能对话助手,它可以在单次对话中处理高达上万个词汇量的上下文。它致力于提供即时、精准、全面地回答用户的各类问题,是一个专业的AI助手。
Claude由Anthropic公司开发,Anthropic是一家人工智能安全和研究公司,致力于建立可靠的、可解释的、可操纵的人工智能系统,公司的创始团队来自于OpenAI2。
Claude提供了两种访问方式,API和Slack机器人。API访问方式需要申请并等待通过,通过后测试时的并发限制为1,用于生产时需要与Anthropic协商具体限速。Claude目前有两个版本,一个是功能强大的版本Claude,擅长于从复杂的对话和创造性的内容生成到详细的指令跟随的广泛任务;一个是速度更快,价格更优的Claude Instant,它也可以处理随意对话、文本分析、摘要和文档问答2。
Claude in Slack目前是beta版本,不收费。Claude目前不支持embedding,Anthropic推荐使用SBERT生成句子embedding2。
Claude目前存在一些缺陷,包括以下几点:
Claude对之前的对话没有任何记忆
Claude经常在复杂的算术和推理中出错
Claude有时会产生幻觉或编造信息和细节
Claude没有联网
Claude的训练数据是两年前的
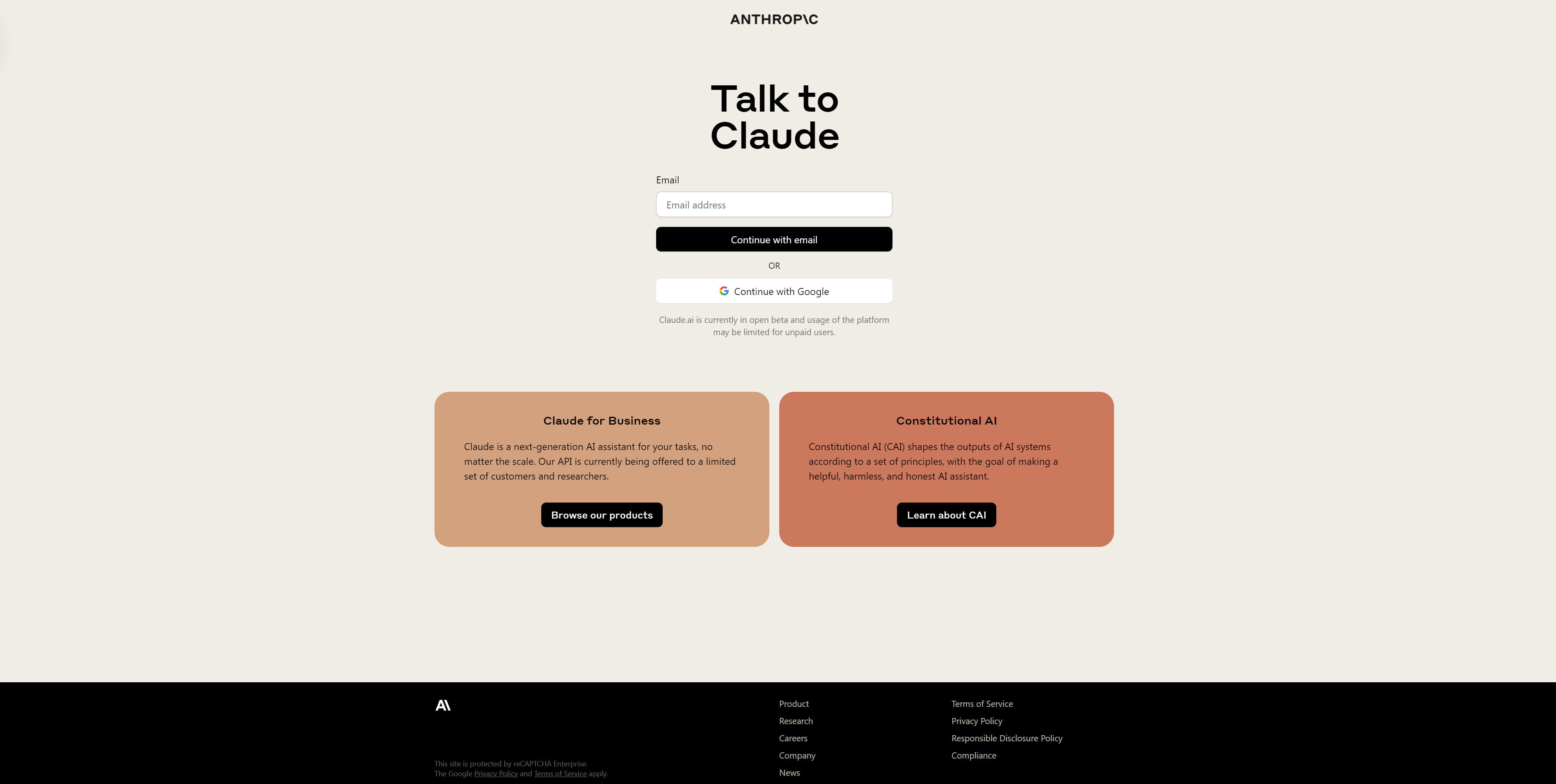
Claude for Business
Claude is a next-generation AI assistant for your tasks, no matter the scale. Our API is currently being offered to a limited set of customers and researchers.
Browse our products
Constitutional AI
Constitutional AI (CAI) shapes the outputs of AI systems according to a set of principles, with the goal of making a helpful, harmless, and honest AI assistant.
Learn about CAI
数据统计
数据评估
本站血鸟导航提供的Claude相关数据内容都来源于网络或站长收集,不保证外部链接和内容的准确性和完整性,同时,对于该外部链接的指向,不由血鸟导航实际控制,在2023年7月22日 下午4:09收录时,该网页上的内容,都属于合规合法,后期网页的内容如出现违规或不对称,欢迎联系我们邮箱进行删除或更改,血鸟导航不承担任何责任。
相关导航







 赣公网安备36020002000448号
赣公网安备36020002000448号