










青岛有线网上营业厅是一个提供有线电视和宽带融合服务的在线平台。我们致力于为用户提供高质量的电视节目和快速稳定的宽带网络,以满足用户对数字娱乐和网络通信的需求。
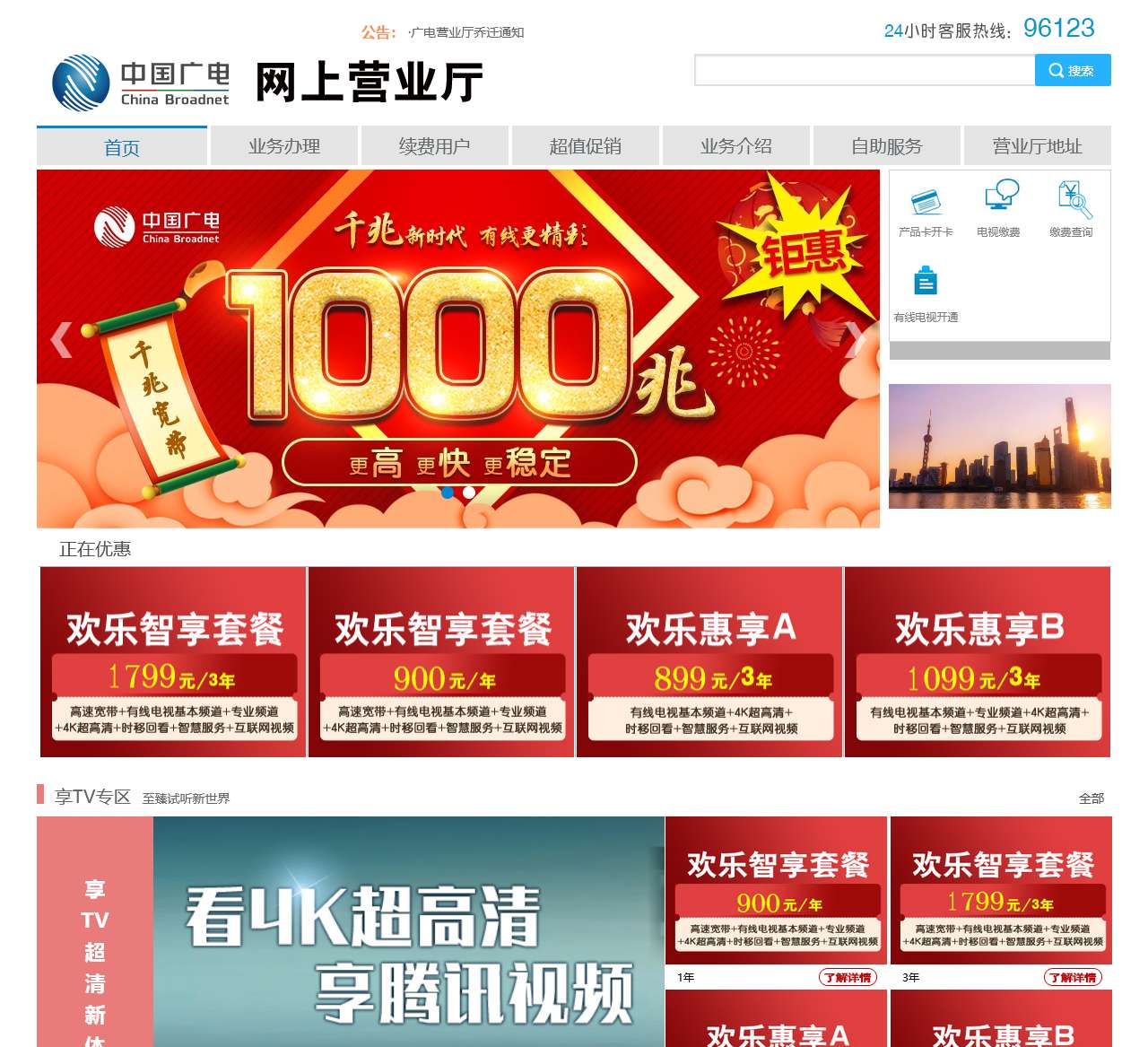
在我们的网站首页上,您可以找到以下主要业务办理和产品信息:
-
有线电视费:您可以了解并缴纳有线电视的费用,确保您的账户保持正常。
-
有线电视套餐:我们提供多种有线电视套餐选择,满足不同用户的需求和偏好。
-
有线电视开通:如果您是新用户,您可以在这里了解如何开通有线电视服务,并获取更多相关信息。
-
硬件产品:我们还提供各种硬件产品,如享TV专区,可以提升您观看电视节目的体验。
-
宽带融合套餐:我们的宽带融合套餐将宽带和有线电视服务合并在一起,方便用户进行综合管理和支付。
-
纯宽带:如果您只需要宽带上网服务,我们也提供纯宽带套餐供您选择。
-
续费:对于现有用户,您可以在网站上方便地进行有线电视和宽带续费。
-
专业频道:我们提供多个专业频道,包括文广点播和青岛点播等,为您提供更多精彩内容选择。
-
首映厅:在我们的首映厅中,您可以欣赏到最新的电影、电视剧等影视作品。
除了以上业务介绍,我们还提供一些自助服务,方便用户进行在线办理和支付。同时,您可以在网站上找到营业厅的地址和营业时间,以及联系方式和区市分公司的相关信息。
我们致力于提供全方位的优质服务,让用户享受到全新的电视观影和网络体验。感谢您选择青岛有线网上营业厅!
- 公司名称法定代表人注册资本注册时间
- 青岛有线电视网络有限公司江范森 8000万2000-02-18
-
备案信息
单位名称:青岛有线电视网络有限公司
单位性质:企业
网站备案:鲁ICP备13027643号-3
网站名称:青岛有线网络中心网站
网站首页:qcn.com.cn
-
服务器
Ip地址:202.136.60.5
服务器地址:
服务器类型: nginx
页面类型: text/html
响应时间:30毫秒
-
域名
域名:qcn.com.cn
域名注册商:阿里云计算有限公司(万网)
域名服务器:
创建时间:2005年03月18日
到期时间:2020年03月18日
数据统计
相关导航







 赣公网安备36020002000448号
赣公网安备36020002000448号